Wordssimilarity¶
Words Similarity¶
Abstract¶
We come into a case, where have a dataset containing a object column which are keywords of item’s features.
Each feature in this column, describe how this item is special from the other items.
But the case here, some of the featurs are duplicated because of different syntax like extra-word added or removed.
For exmaple: air-conditioner, airconditioner, conditioner. So all these features could be replaced by a single keyword ‘conditioner’.
So we need to do something like normalizing the features in that column, and re-assign the normalized keywords for all the features.
Methadology: Levenshtein Distance¶
A required here, is to measure the similarity between words, so the matched words should be reduced into a single words.
This problem is converted to the number of edits to convert from word to the other, a solution for this is Levenshtein Distance.
This problem is a Dynamic programming problem.
Informally, the Levenshtein distance between two words is the minimum number of single-character edits (insertions, deletions or substitutions) required to change one word into the other.
So this distance calculate how different two strings are, So the higher the number, the more different the strings are.
It is named after the Soviet mathematician Vladimir Levenshtein, who considered this distance in 1965
Diving Deep¶
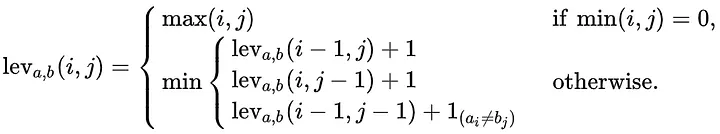
Let’s understand what a, b, i, and j stand for:
a = string #1
b = string #2
i = the terminal character position of string #1
j = the terminal character position of string #2.
The positions are 1-indexed. Consider the below example where we compare string“cat” with string “cap”:

From the equation: The conditional (aᵢ ≠bⱼ)
aᵢ refers to the character of string a at position i
bⱼ refers to the character of string b at position j
We want to check that these are not equal, because if they are equal, no edit is needed, so we should not add 1. Conversely, if they are not equal, we want to add 1 to account for a necessary edit.
Example¶
Let’s take an example between ‘sitting’ & ‘kitten’.

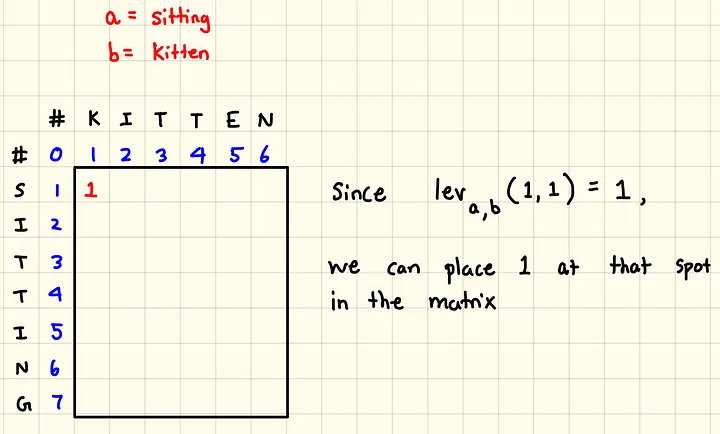
So following up, The calculated metrix

Implementation: fuzzywuzzy¶
In Python, there is a developed package designed to do that similatity calculation called fuzzywuzzy, which in deep calculate the Levenshtein distance.
from fuzzywuzzy import fuzz