Encoder Decoder¶
MT - Machine Translator¶
In the journy of NLP, short for Natural Langauge Processing, starting with basic architecture of an encoder-decoder model, that we will apply a neural network in.
What is Machine Translator?¶
Machine translation is the task of automatically converting source text in one language to text in another language. Given a sequence of text in a source language, there is no one single best translation of that text to another language. This is because of the natural ambiguity and flexibility of human language. This makes the challenge of automatic machine translation difficult, perhaps one of the most difficult in artificial intelligence. — “Machine Learning Mastery” by Jason Brownlee, Ph.D. [1]
What is Neural Machine Translator?¶
Initially machine translation (MT) problems were faced using statistical approaches, based mainly on Bayes probabilities. But when neural networks became more powerful and popular, researchers began to explore the capabilities of this technology and new solutions were found. It is called neural machine translation (NMT).
From the above, we can deduce that NMT is a problem where we process an input sequence to produce an output sequence — that is, a sequence-to-sequence (seq2seq) problem. The encoder-decoder architecture for recurrent neural networks is the standard method.
Encoder-Decoder A Basic Approach¶
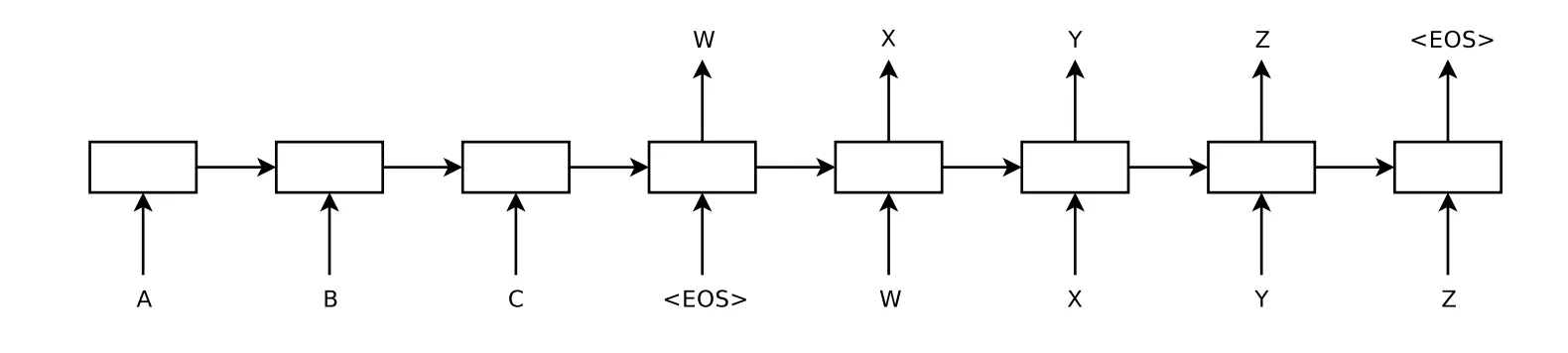 Image source: Sequence to Sequence Learning with Neural Networks
Image source: Sequence to Sequence Learning with Neural Networks
The seq2seq model consists of two subnetworks, the encoder and the decoder. The encoder, on the left hand, receives sequences from the source language as inputs and produces, as a result, a compact representation of the input sequence, trying to summarize or condense all of its information. Then that output becomes an input or initial state to the decoder, which can also receive another external input.
At each time step, the decoder generates an element of its output sequence based on the input received and its current state, as well as updating its own state for the next time step.
This illustate the 4 arrows (two inputs: input received & its current state, two outputs: output sequence & updating its own state for next step) from a decoder unit.
Input & Output Shape¶
The input and output sequences are of fixed size, but they don’t have to match the length of the input sequence may differ from that of the output sequence.
Critical Point: Input Vector¶
The critical point of this model is how to get the encoder to provide the most complete and meaningful representation of its input sequence in a single output element to the decoder because this vector or state is the only information the decoder will receive from the input to generate the corresponding output. The longer the input, the harder it’ll be to compress into a single vector.
Tensorflow Implementation¶
https://www.tensorflow.org/text/tutorials/nmt_with_attention
Credits¶
https://betterprogramming.pub/a-guide-on-the-encoder-decoder-model-and-the-attention-mechanism-401c836e2cdb